AI tools for Computer Vision object detection
Related Tools:
Ripik.ai
Ripik.ai is an applied AI company developing computer vision agents—an automated pair of eyes for industries like steel, cement, and chemicals. These AI-driven agents provide 24/7 monitoring with 95%+ accuracy, enabling real-time decision-making while eliminating human error and inefficiencies. Ripik's Computer Vision AI Platform offers solutions for material, process, and equipment monitoring, driving higher throughput, improved energy efficiency, and enhanced quality, delivering direct and measurable gains across industrial operations.
Grok-1.5 Vision
Grok-1.5 Vision (Grok-1.5V) is a groundbreaking multimodal AI model developed by Elon Musk's research lab, x.AI. This advanced model has the potential to revolutionize the field of artificial intelligence and shape the future of various industries. Grok-1.5V combines the capabilities of computer vision, natural language processing, and other AI techniques to provide a comprehensive understanding of the world around us. With its ability to analyze and interpret visual data, Grok-1.5V can assist in tasks such as object recognition, image classification, and scene understanding. Additionally, its natural language processing capabilities enable it to comprehend and generate human language, making it a powerful tool for communication and information retrieval. Grok-1.5V's multimodal nature sets it apart from traditional AI models, allowing it to handle complex tasks that require a combination of visual and linguistic understanding. This makes it a valuable asset for applications in fields such as healthcare, manufacturing, and customer service.

Ultralytics YOLO
Ultralytics YOLO is an advanced real-time object detection and image segmentation model that leverages cutting-edge advancements in deep learning and computer vision. It offers unparalleled performance in terms of speed and accuracy, making it suitable for various applications and easily adaptable to different hardware platforms. The comprehensive Ultralytics Docs provide resources to help users understand and utilize its features and capabilities, catering to both seasoned machine learning practitioners and newcomers to the field.
Roboflow
Roboflow is an AI tool designed for computer vision tasks, offering a platform that allows users to annotate, train, deploy, and perform inference on models. It provides integrations, ecosystem support, and features like notebooks, autodistillation, and supervision. Roboflow caters to various industries such as aerospace, agriculture, healthcare, finance, and more, with a focus on simplifying the development and deployment of computer vision models.
Sighthound
Sighthound is an AI-powered video solutions provider that specializes in solving complex video AI problems at scale. Their products, such as Sighthound ALPR+ for Automatic License Plate Recognition and Sighthound Redactor for Video Redaction, leverage deep learning technology to unlock valuable user insights, reduce operational costs, and increase revenue in the privacy and vehicle recognition space. With a focus on simplicity and customer support, Sighthound offers easy integration of their AI products through simple-to-use APIs.

Viso Suite
Viso Suite is a no-code computer vision platform that enables users to build, deploy, and scale computer vision applications. It provides a comprehensive set of tools for data collection, annotation, model training, application development, and deployment. Viso Suite is trusted by leading Fortune Global companies and has been used to develop a wide range of computer vision applications, including object detection, image classification, facial recognition, and anomaly detection.
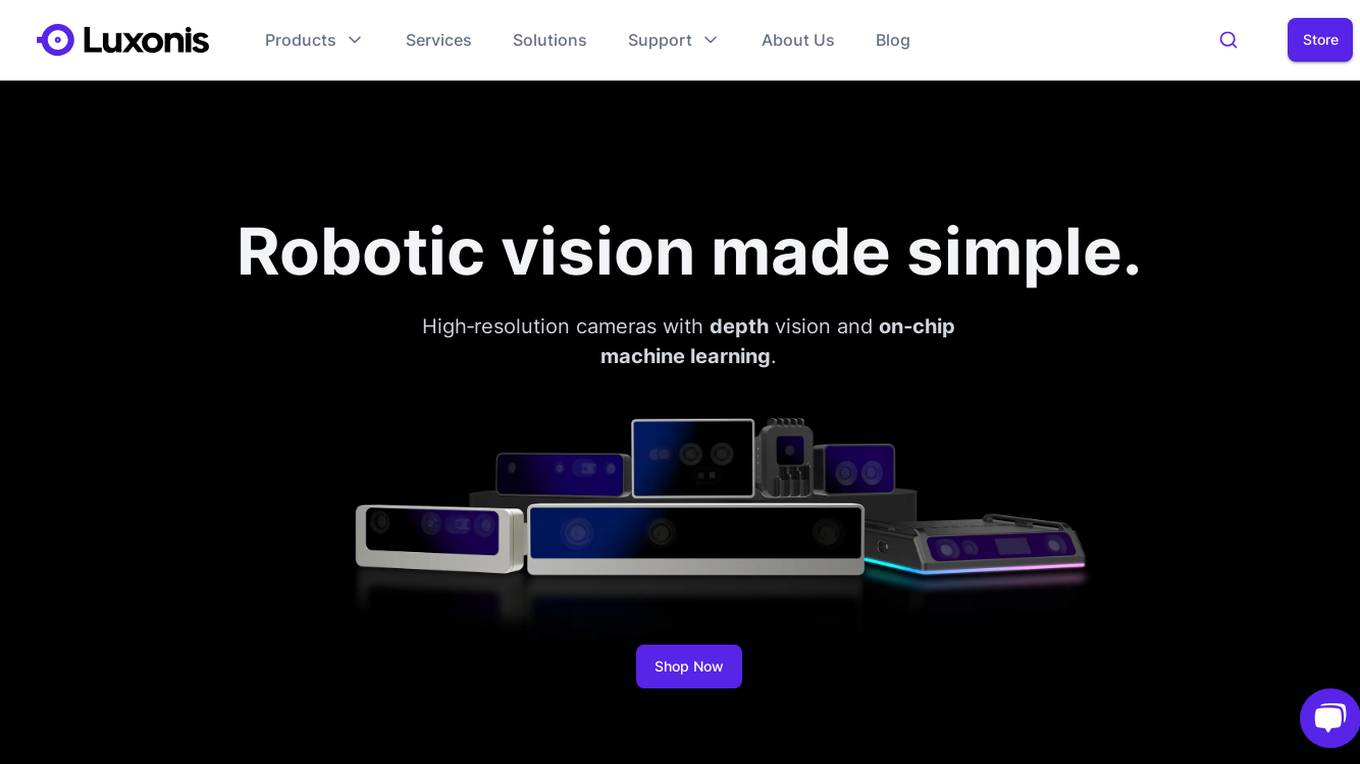
Luxonis
Luxonis is a platform that offers robotic vision solutions through high-resolution cameras with depth vision and on-chip machine learning capabilities. Their products include OAK Cameras and Modules, providing features like Stereo Depth Sensing, Computer Vision, Artificial Intelligence, and Cloud Management. Luxonis enables the development of computer vision products and companies by offering performant and affordable hardware solutions. The platform caters to enterprises and hobbyists, empowering them to easily build embedded vision systems.
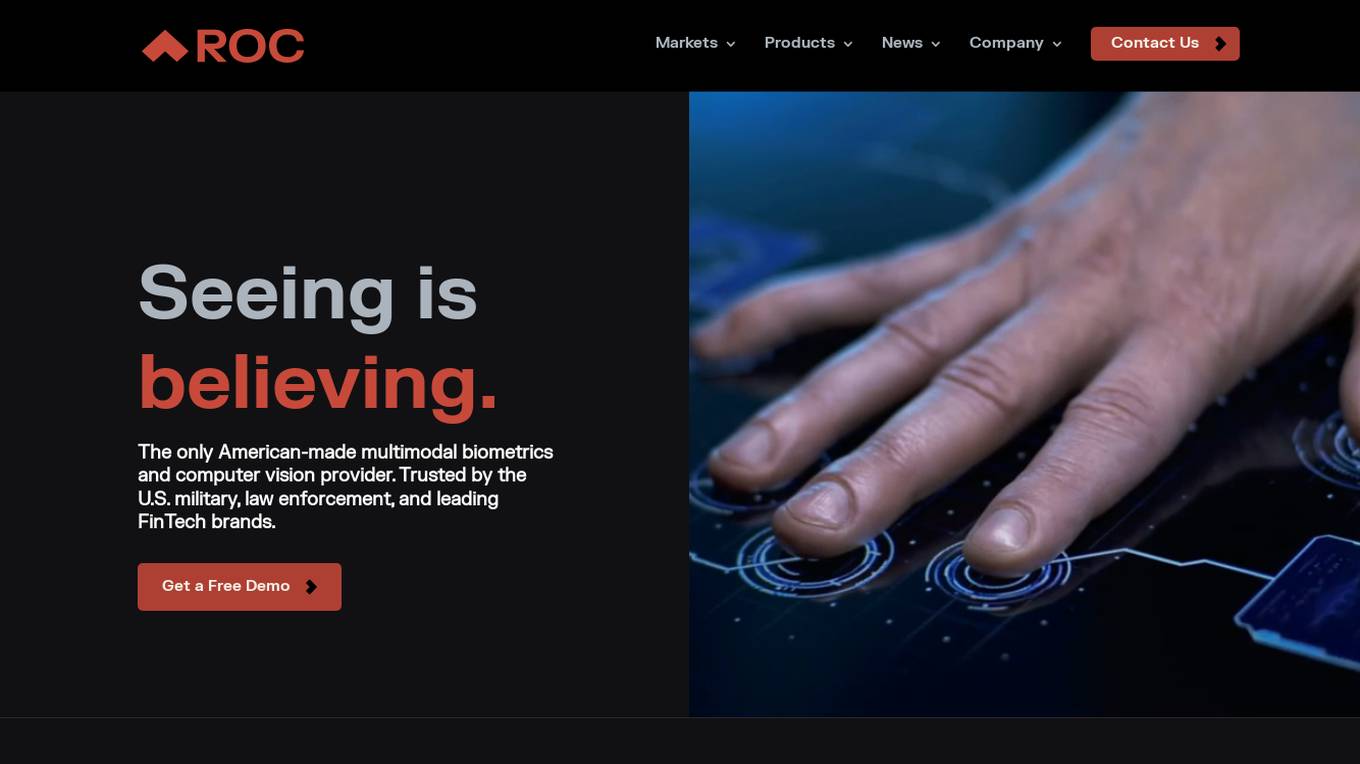
Rank One Computing
Rank One Computing (ROC) is an American-made provider of multimodal biometrics and computer vision solutions, specializing in face recognition, fingerprint recognition, and artificial intelligence technologies. Trusted by the U.S. military, law enforcement, and leading FinTech brands, ROC offers top-ranked software for identity proofing and threat detection. Their suite of products includes ROC SDK, ROC Watch, and custom enterprise AI development services. With a focus on security and efficiency, ROC aims to make the world safer and more convenient through unbiased and privacy-conscious applications.
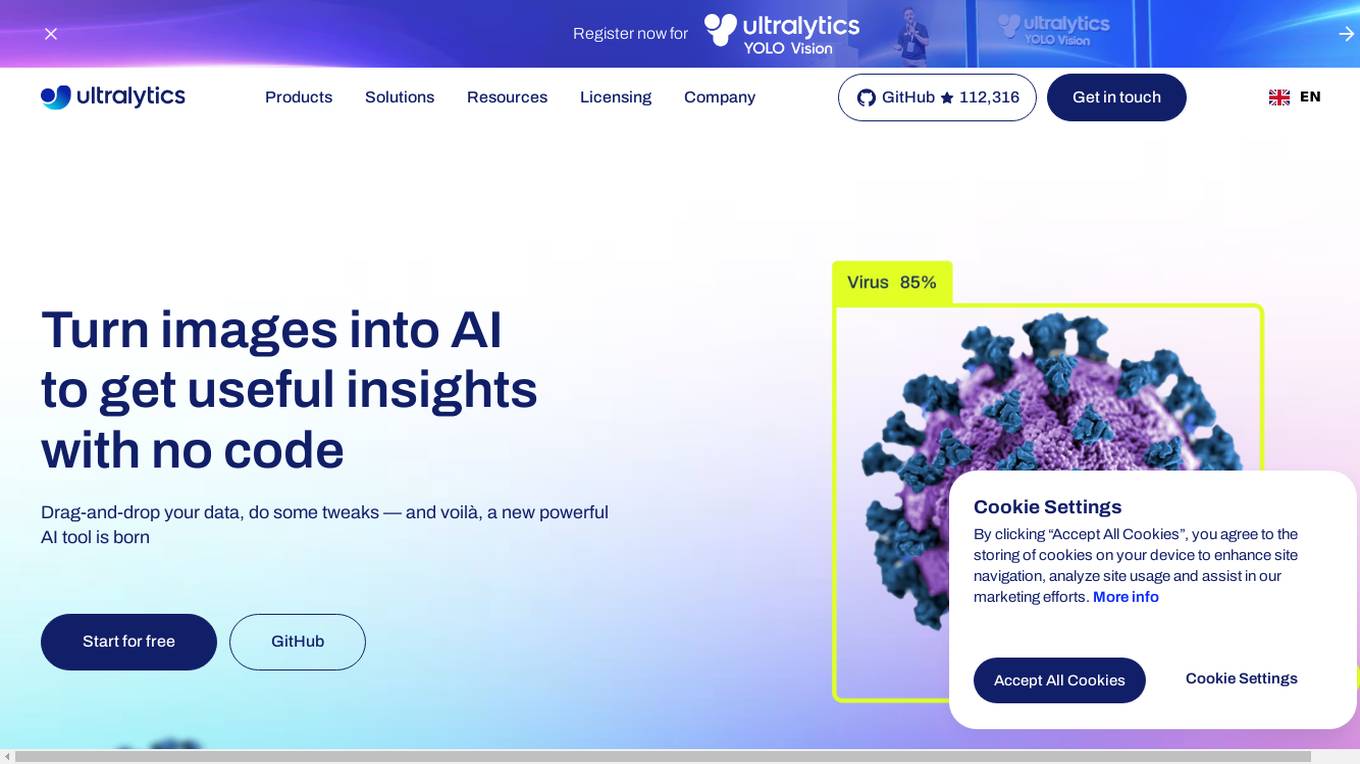
Ultralytics
Ultralytics is an AI tool that revolutionizes the world of Vision AI by enabling users to easily turn images into AI to get useful insights without writing any code. It offers a drag-and-drop interface for data input, model training, and deployment, making it accessible for startups, enterprises, data scientists, ML engineers, hobbyists, researchers, and academics. Ultralytics YOLO, the flagship tool, allows users to train machine learning models in seconds, select from pre-built models, test models on mobile devices, and deploy custom models to various formats. The tool is powered by Ultralytics Python package and is open-source, with a focus on computer vision, object detection, and image classification.
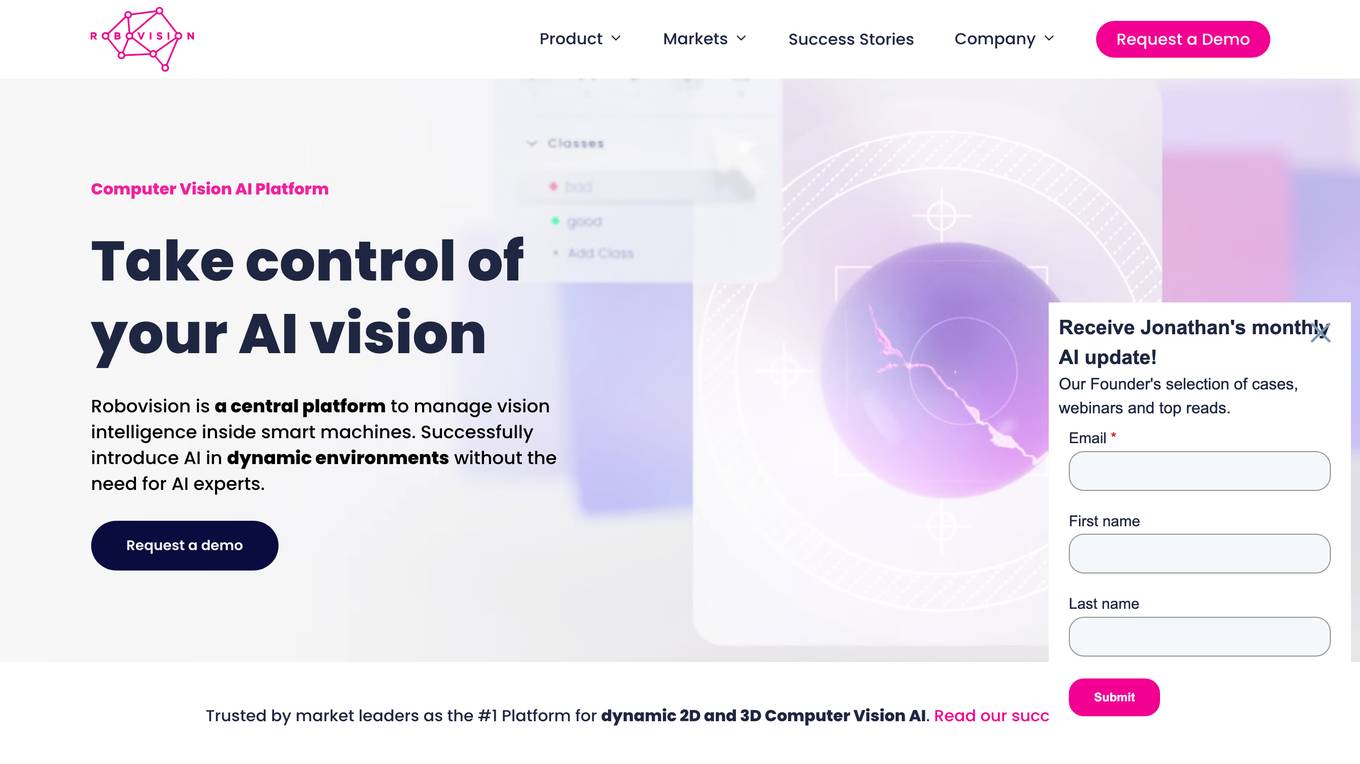
Robovision
Robovision is a central platform to manage vision intelligence inside smart machines. Successfully introduce AI in dynamic environments without the need for AI experts.

OpenCV.ai
OpenCV.ai is a leading provider of computer vision software and services. The company's team of experts has extensive experience in developing optimized large-scale computer vision solutions. OpenCV.ai's expertise is helping businesses grow in a variety of industries, including medicine, manufacturing, and retail. The company's solutions are used by startups and Fortune 500 companies alike.
Clarifai
Clarifai is a full-stack AI developer platform that provides a range of tools and services for building and deploying AI applications. The platform includes a variety of computer vision, natural language processing, and generative AI models, as well as tools for data preparation, model training, and model deployment. Clarifai is used by a variety of businesses and organizations, including Fortune 500 companies, startups, and government agencies.
Clarifai
Clarifai is a full-stack AI platform that provides developers and ML engineers with the fastest, production-grade deep learning platform. It offers a wide range of features, including data preparation, model building, model operationalization, and AI workflows. Clarifai is used by a variety of companies, including Fortune 500 companies and startups, to build AI applications in a variety of industries, including retail, manufacturing, and healthcare.
Landing AI
Landing AI is a computer vision platform and AI software company that provides a cloud-based platform for building and deploying computer vision applications. The platform includes a library of pre-trained models, a set of tools for data labeling and model training, and a deployment service that allows users to deploy their models to the cloud or edge devices. Landing AI's platform is used by a variety of industries, including automotive, electronics, food and beverage, medical devices, life sciences, agriculture, manufacturing, infrastructure, and pharma.
Roboflow
Roboflow is a platform that provides tools for building and deploying computer vision models. It offers a range of features, including data annotation, model training, and deployment. Roboflow is used by over 250,000 engineers to create datasets, train models, and deploy to production.
Joseph Chet Redmon's Computer Vision Platform
The website is a platform maintained by Joseph Chet Redmon, a graduate student working on computer vision. It features information on his projects, publications, talks, and teaching activities. The site also includes details about the Darknet Neural Network Framework, tactics in Coq, and research work. Visitors can learn about computer vision, object recognition, and visual question answering through the resources provided on the site.
Lexset
Lexset is an AI tool that provides synthetic data generation services for computer vision model training. It offers a no-code interface to create unlimited data with advanced camera controls and lighting options. Users can simulate AI-scale environments, composite objects into images, and create custom 3D scenarios. Lexset also provides access to GPU nodes, dedicated support, and feature development assistance. The tool aims to improve object detection accuracy and optimize generalization on high-quality synthetic data.
Datature
Datature is an all-in-one platform for building and deploying computer vision models. It provides tools for data management, annotation, training, and deployment, making it easy to develop and implement computer vision solutions. Datature is used by a variety of industries, including healthcare, retail, manufacturing, and agriculture.
OpenCV
OpenCV is the world's largest computer vision library. It's open source, contains over 2500 algorithms and is operated by the non-profit Open Source Vision Foundation.

Big Vision
Big Vision provides consulting services in AI, computer vision, and deep learning. They help businesses build specific AI-driven solutions, create intelligent processes, and establish best practices to reduce human effort and enable faster decision-making. Their enterprise-grade solutions are currently serving millions of requests every month, especially in critical production environments.

Pixie: Computer Vision Engineer
Expert in computer vision, deep learning, ready to assist you with 3d and geometric computer vision. https://github.com/kornia/pixie

Deep Learning Master
Guiding you through the depths of deep learning with accuracy and respect.
AI Tools Guru
Find the best AI tools. Want to add your tool? Fill the form: https://forms.gle/uqMaC2EFZzh3Y4yT6

DeepCSV
Realiza consultas de Deep Learning basado en el contenido del canal de Youtube DotCSV
Counterfeit Detector
Specialist in authenticating products using the latest computer vision technology by Cypheme.

Jimmy madman
This AI is specifically for Computer Vision usage, specifically realated to PCB component identification
Street Sign Recognition GPT
Friendly and professional guide for street sign app development.
Identify movies, dramas, and animations by image
Just send us an image of a scene from a video work and i will guess the name of the work!

ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024

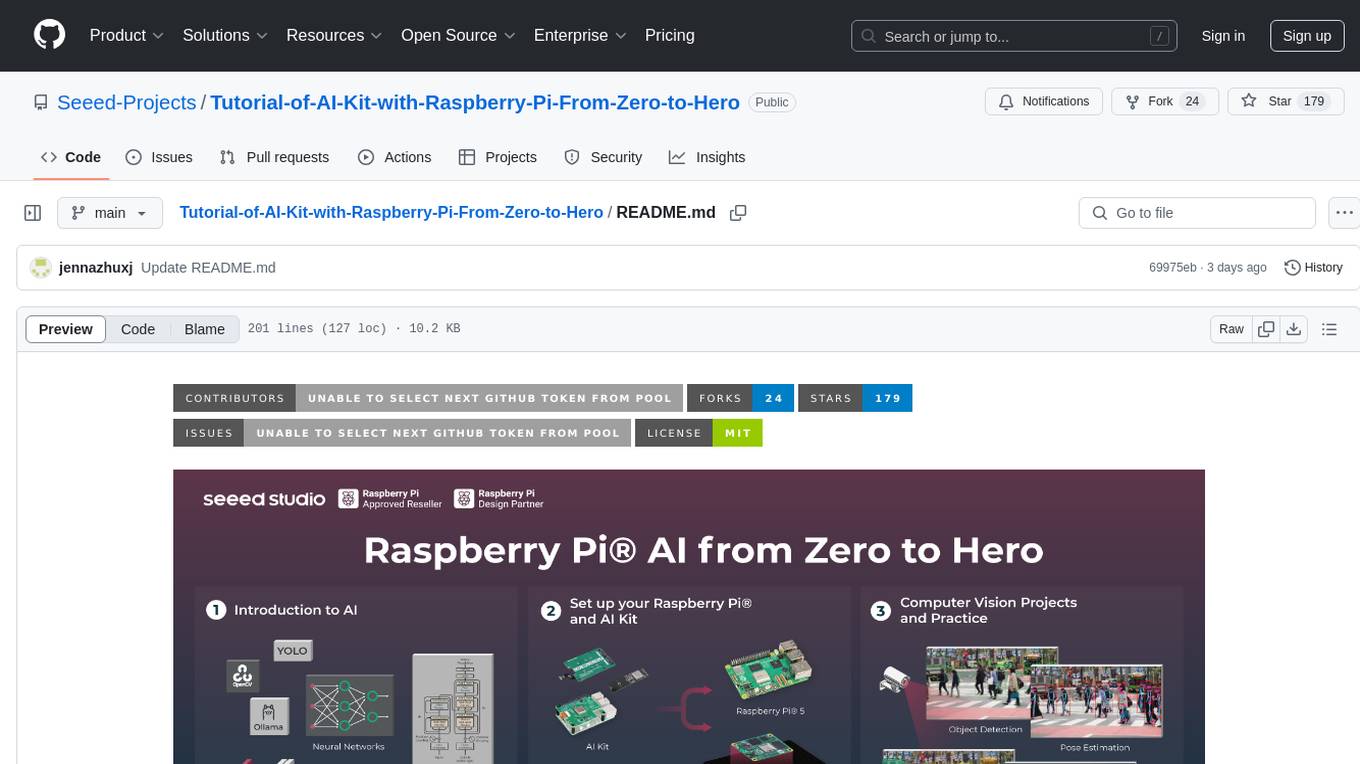
Tutorial-of-AI-Kit-with-Raspberry-Pi-From-Zero-to-Hero
This course is designed to teach you how to harness the power of AI on the Raspberry Pi, with a focus on using an AI kit for computer vision tasks. Learn to integrate AI into IoT applications, from object detection to visual recognition. Suitable for hobbyists, students, and professionals to bring AI-driven solutions to life on resource-constrained devices like the Raspberry Pi.

Awesome-Segment-Anything
Awesome-Segment-Anything is a powerful tool for segmenting and extracting information from various types of data. It provides a user-friendly interface to easily define segmentation rules and apply them to text, images, and other data formats. The tool supports both supervised and unsupervised segmentation methods, allowing users to customize the segmentation process based on their specific needs. With its versatile functionality and intuitive design, Awesome-Segment-Anything is ideal for data analysts, researchers, content creators, and anyone looking to efficiently extract valuable insights from complex datasets.
Awesome-LLM-3D
This repository is a curated list of papers related to 3D tasks empowered by Large Language Models (LLMs). It covers tasks such as 3D understanding, reasoning, generation, and embodied agents. The repository also includes other Foundation Models like CLIP and SAM to provide a comprehensive view of the area. It is actively maintained and updated to showcase the latest advances in the field. Users can find a variety of research papers and projects related to 3D tasks and LLMs in this repository.
awesome-object-detection-datasets
This repository is a curated list of awesome public object detection and recognition datasets. It includes a wide range of datasets related to object detection and recognition tasks, such as general detection and recognition datasets, autonomous driving datasets, adverse weather datasets, person detection datasets, anti-UAV datasets, optical aerial imagery datasets, low-light image datasets, infrared image datasets, SAR image datasets, multispectral image datasets, 3D object detection datasets, vehicle-to-everything field datasets, super-resolution field datasets, and face detection and recognition datasets. The repository also provides information on tools for data annotation, data augmentation, and data management related to object detection tasks.
CompressAI-Vision
CompressAI-Vision is a tool that helps you develop, test, and evaluate compression models with standardized tests in the context of compression methods optimized for machine tasks algorithms such as Neural-Network (NN)-based detectors. It currently focuses on two types of pipeline: Video compression for remote inference (`compressai-remote-inference`), which corresponds to the MPEG "Video Coding for Machines" (VCM) activity. Split inference (`compressai-split-inference`), which includes an evaluation framework for compressing intermediate features produced in the context of split models. The software supports all the pipelines considered in the related MPEG activity: "Feature Compression for Machines" (FCM).

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.
landingai-python
The LandingLens Python library contains the LandingLens development library and examples that show how to integrate your app with LandingLens in a variety of scenarios. The library allows users to acquire images from different sources, run inference on computer vision models deployed in LandingLens, and provides examples in Jupyter Notebooks and Python apps for various tasks such as object detection, home automation, satellite image analysis, license plate detection, and streaming video analysis.
InsPLAD
InsPLAD is a dataset and benchmark for power line asset inspection in UAV images. It contains 10,607 high-resolution UAV color images of seventeen unique power line assets with six defects. The dataset is used for object detection, defect classification, and anomaly detection tasks in computer vision. InsPLAD offers challenges like multi-scale objects, intra-class variation, cluttered background, and varied lighting conditions, aiming to improve state-of-the-art methods in the field.
yolo-flutter-app
Ultralytics YOLO for Flutter is a Flutter plugin that allows you to integrate Ultralytics YOLO computer vision models into your mobile apps. It supports both Android and iOS platforms, providing APIs for object detection and image classification. The plugin leverages Flutter Platform Channels for seamless communication between the client and host, handling all processing natively. Before using the plugin, you need to export the required models in `.tflite` and `.mlmodel` formats. The plugin provides support for tasks like detection and classification, with specific instructions for Android and iOS platforms. It also includes features like camera preview and methods for object detection and image classification on images. Ultralytics YOLO thrives on community collaboration and offers different licensing paths for open-source and commercial use cases.
osm-ai-helper
OSM-AI-helper is a Blueprint by Mozilla.ai designed to assist users in mapping features in OpenStreetMap using object detection and image segmentation models. It provides tools for identifying and mapping various features, such as swimming pools, in OpenStreetMap. Users can also create custom datasets and fine-tune models for different use cases. The project is licensed under the AGPL-3.0 License and welcomes contributions from the community.
viseron
Viseron is a self-hosted, local-only NVR and AI computer vision software that provides features such as object detection, motion detection, and face recognition. It allows users to monitor their home, office, or any other place they want to keep an eye on. Getting started with Viseron is easy by spinning up a Docker container and editing the configuration file using the built-in web interface. The software's functionality is enabled by components, which can be explored using the Component Explorer. Contributors are welcome to help with implementing open feature requests, improving documentation, and answering questions in issues or discussions. Users can also sponsor Viseron or make a one-time donation.

learnopencv
LearnOpenCV is a repository containing code for Computer Vision, Deep learning, and AI research articles shared on the blog LearnOpenCV.com. It serves as a resource for individuals looking to enhance their expertise in AI through various courses offered by OpenCV. The repository includes a wide range of topics such as image inpainting, instance segmentation, robotics, deep learning models, and more, providing practical implementations and code examples for readers to explore and learn from.

pytorch-grad-cam
This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.
awesome-openvino
Awesome OpenVINO is a curated list of AI projects based on the OpenVINO toolkit, offering a rich assortment of projects, libraries, and tutorials covering various topics like model optimization, deployment, and real-world applications across industries. It serves as a valuable resource continuously updated to maximize the potential of OpenVINO in projects, featuring projects like Stable Diffusion web UI, Visioncom, FastSD CPU, OpenVINO AI Plugins for GIMP, and more.
VisioFirm
VisioFirm is an open-source, AI-powered image annotation tool designed to accelerate labeling for computer vision tasks like classification, object detection, oriented bounding boxes (OBB), segmentation and video annotation. Built for speed and simplicity, it leverages state-of-the-art models for semi-automated pre-annotations, allowing you to focus on refining rather than starting from scratch. Whether you're preparing datasets for YOLO, SAM, or custom models, VisioFirm streamlines your workflow with an intuitive web interface and powerful backend. Perfect for researchers, data scientists, and ML engineers handling large image datasets—get high-quality annotations in minutes, not hours!
albumentations
Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to increase the quality of trained models. The purpose of image augmentation is to create new training samples from the existing data.